Approaching Debugging
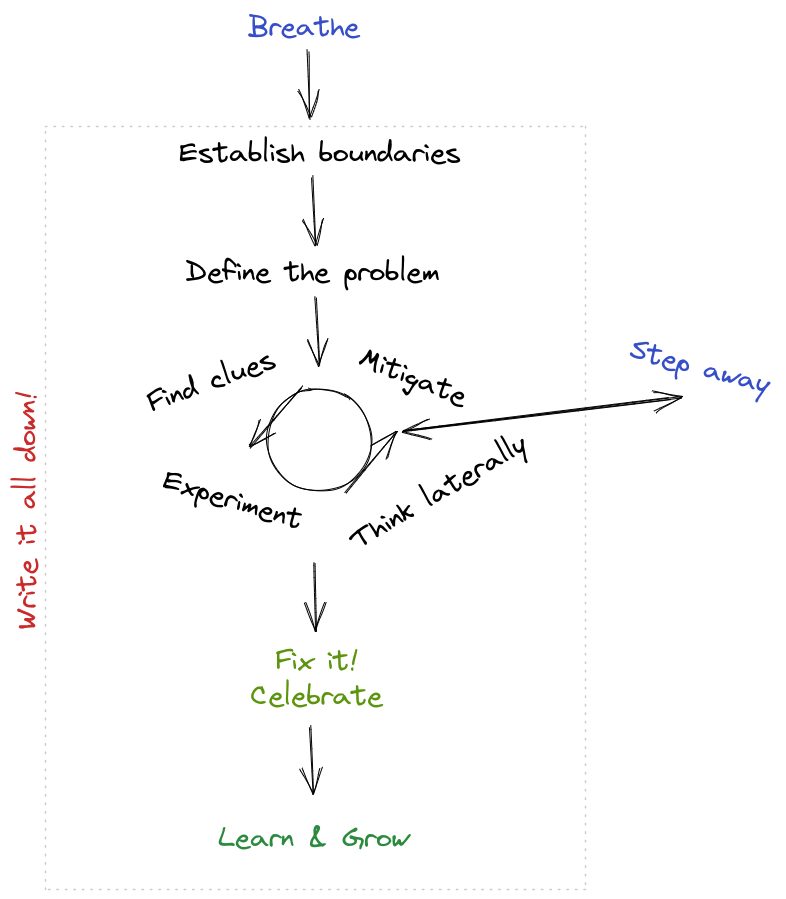
Figure 1: Spoiler
This is my approach to debugging. There are many like it, but this one is mine1. 1: I've chosen to write about this as effectively being a singleplayer game, but making it multiplayer – particularly with experienced players – can turn out to be significantly better for your time to resolution, as well as your own sanity.
Approaching debugging
Breathe
The first (and most important) aspect of tackling a thorny problem is having the right mindset.
I personally like to approach bugs calmly, with a keen sense of curiosity and (possibly undue) optimism, because frustration, panic and pessimism can all end up causing tunnel vision, making the problem much, much harder to fix.
It's just code. You can fix it.
Establish boundaries
Understanding the problem is obviously important, but there's also a cost/benefit analysis to do first: how important is it? How much time (and how many engineers) are you willing to spend to fix it?
Is there a threshold at which it would be better to patch over the problem instead? Or, is it better to leave it unfixed2? 2: Leaving it unfixed is not a decision to be taken lightly: bugs, particularly heisenbugs tend to compound rapidly, and can render a code base impossible to work with or improve. With this in mind, incurring technical debt should be seen as a very explicit, conscious decision.
Write everything down
The process of debugging often involves switching between extremely involved depth-first and wide breadth-first searches when diagnosing the issue. In these cases, writing things down acts as an additional form of memory, and helps a lot when you need to be able to quickly bring additional people up to speed.
Most importantly, though, it can also help highlight what hasn't been tried yet.
Written notes also come in handy after the problem has been solved, for the purposes of retrospectives and spreading knowledge, as well as building a nice collection of war stories.
Define the problem
Make sure you clearly understand and are able to describe the issue: what's the actual behavior and what's the expected behavior?
Oftentimes, I'll find something I had considered a bug to be the result of complex systems interacting in unexpected but intended ways.
Mitigate
All through the process, you're going to constantly need to evaluate if/when you need to mitigate the problem (even if you don't quite know the right solution yet).
A common solution is to revert to a known-good state; patch around the problem, or disable a specific feature while the behavior is being fixed.
Some things you should consider when making this decision are your confidence in the mitigation, the ease and speed of deployment, the urgency of the problem and the likelihood of finding a "better" fix.
Find clues
Bugs can have several distinctive characteristics: quickly identifying them can serve to speed up your debugging process significantly.
Some common tactics to apply:
- Are there any hints in logs or telemetry?
- Where does it happen? In specific devices, only in production, only in the development environment, everywhere?
- Who does it occur for? Are there any specific characteristics for affected users/identifying units for the bug? Instrumentation can be extremely valuable here.
- Does it reproduce consistently? Is it (shudder) a race condition?
- When did it start happening? What changed around that time?
- Visualize any available data so that you can look for patterns.
Ideally, you'll have enough instrumentation, telemetry and samples to be able to answer each of these questions quickly. Alternatively, though, collecting a small set of examples can also significantly serve to reduce the search space.
Experiment
Based on the clues you've carefully written down, you might already have some intuition of where the problem is potentially happening: this step relies on your understanding of the system.
Another way to build this intuition is to look for the first point at which reality diverges from your mental model of the system: you need to understand why.
Make a hypothesis first, predict what will happen, and then go and apply the change. Change only one thing at a time to make sure you are able to clearly reason around cause and effect.
Figure out how to test changes cheaply and have a tight feedback loop. Consistently look for reasons to disprove your hypothesis.
There will be times when there are multiple tiny bugs coming together in wonderfully imaginative ways, which will then require you to apply multiple fixes. Remember to maintain a record of everything that's been tried!
Think laterally
Sometimes things just don't fit together, or there's just no time to play "scientist" and experiment. In these kinds of scenarios, you can always try and brute force the solution by treating the system like a black box and looking at it from the outside.
By looking at when the problem started happening, you can then begin to understand what changed. Look through the commit history; look at the changes in the surrounding systems; look through updates to hosts and other related applications. Perhaps something interesting happened in the world, causing load on the service to spike and the servers to fall over.
If nothing in the change logs or release notes looks out of the ordinary, then it's time to fall back to binary search. Simply revert the system to a known good state, and keep walking it forward till it starts failing; alternatively, you can also go backwards till it starts working.
Step away
If absolutely nothing else is working, then simply taking a break from the problem and letting your subconscious deal with it s something that can oftentimes turn out to produce really good results.
Distract yourself with other (preferably nontechnical) things: go for a walk, move away from the computer, doodle and recover.
Fix, verify and celebrate!
Once you have an acceptable fix, now it's time for you to release it. I hope you have established some ways to quickly and smoothly release your code (or have plans to make it that way). Validate that the both actual and expected behaviors match up.
Then, celebrate! It's finally time to set aside a few moments to savor your victory, recover from the stress and take a well-earned break.
Things are all right with the world again.
Learn from it!
You aren't done yet, though.
There's still a lot to learn from a complex bug, and a lot to do in order to to make dealing with the next one simpler.
Build your own knowledge
Learning and becoming more familiar with tools that could help debug the problem sooner can help speed up your process significantly the next time around.
Write a postmortem: build others' knowledge
For meaningful investigations, writing them up and sharing them afterwards helps teach others, and has the potential to speed them up significantly in the future as well.
Make it impossible to ever happen again
Change the system's design to make it completely impossible for the same situation to reoccur. Add the right regression tests to prevent it from ever happening again, as well as the right unit tests to exercise the responsible piece of code.
Alternatively, you can also simply simple delete the outdated and unused abstraction (if possible).
Make it very easy to debug if it ever does happen again
Some of the clues you found might have proven to be much more helpful than others. Ask yourself: if you had to debug this all over again, what signal would have made the whole thing trivial to understand and fix?
Add the telemetry, logs, alarms or dashboards that would make this bug a trivial nuisance, if it dared to show itself again.3 3: Here's an exercise I actually use every time I add logging to a system: I hypothesize debugging an issue in the surrounding code, and then consider which information would help me. Then I add the logs.
War stories
While I like to believe that I've certainly earned my software debugging scars in my time, I'm sure yours are just as (if not more) impressive, and I'd absolutely love to hear about some of the strange issues you've solved, what you do differently from my approach, and any impressive tricks you use to figure things out: email, Twitter.
History
- 2021-07-21: Edited by Lindsey W.
- 2021-01-17: Tweaked based on feedback from Michael Lynch.
- 2020-05-30: Published.